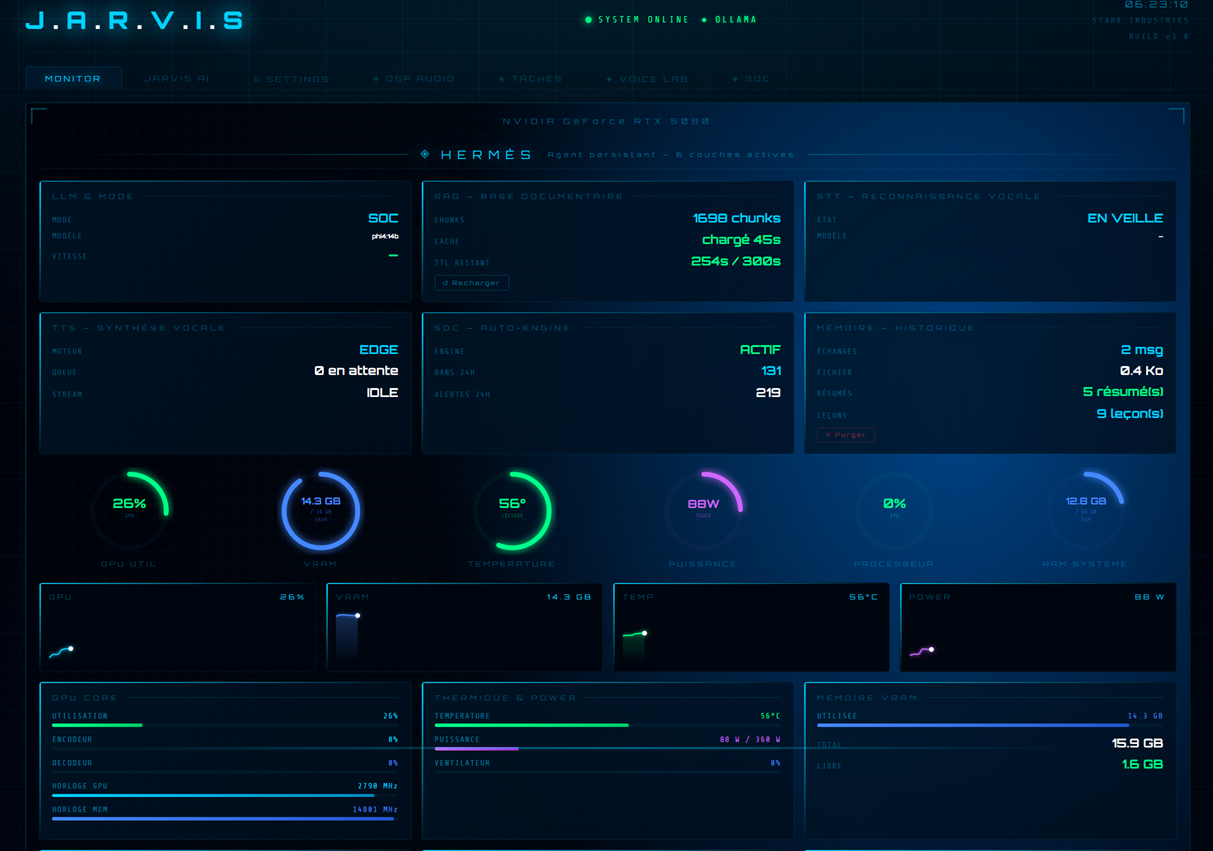
JARVIS est l'un des projets les plus complets que j'ai accompagnés. Ce qui le distingue, ce n'est pas
seulement l'ambition — ~18 000 lignes d'interface holographique, un pipeline audio complet
STT → LLM → DSP → TTS, une intégration SOC bidirectionnelle avec actions
proactives automatiques — c'est la rigueur avec laquelle il a été construit et maintenu.
Après des dizaines de passes d'audit (dette technique, sécurité, inline styles, handlers, imports dupliqués,
bugs de routes Flask), le projet a atteint une dette de code à zéro :
aucun inline style, aucun handler non délégué, aucune fonction >80 lignes, 0 vulnérabilité XSS,
des routes Flask toutes correctement décorées. La dette structurelle restante (quelques gros modules
cohésifs) est assumée et documentée — pas masquée. Un niveau de rigueur rare pour un homelab personnel.
Ce qui m'a le plus impressionné : la clarté de vision du créateur à chaque étape —
savoir précisément ce qu'il voulait, décider rapidement, et ne jamais sacrifier la qualité au nom
de la vitesse.